Getting started with Hive
This page contains information to help you get started with Hive in Semarchy xDI.
Connect to your data
The first step, when you want to work with Hive in Semarchy xDI, consists of creating and configuring the Hive Metadata.
Below, a quick overview of a fully configured Hive Metadata.

Create the Metadata
Create first the Hive Metadata, as usual, by selecting the Hive technology in the Metadata Creation Wizard.
Choose a name for this Metadata and go to next step.
Configure the Metadata
Kerberos security
When working with Kerberos secured Hadoop clusters, connections will be protected, and you’ll therefore need to specify the credentials and necessary information to perform the Kerberos connection.
If your cluster is NOT secured with kerberos, you can jump to the next section.
If your cluster is secured with Kerberos, close the server Wizard popup (if it is displayed), and follow the steps below before trying to connect and reverse Hive objects.
-
Create a new Kerberos Metadata (or use an existing one)
-
Define inside the Kerberos Principal to use for Hive
-
Drag and drop it in the Hive Metadata
-
Rename the Metadata Link to 'KERBEROS'

| Refer to Getting started with Kerberos for more information. |
Server properties
You are now ready to configure the JDBC properties that will be used to connect to Hive.
We’re going to use the Server Wizard to configure everything.
Define the JDBC properties to connect to Hive and click then on Connect when it is done.

| If the Server Wizard popup is not displayed (if you closed it for configuring Kerberos, or any other reason), you can open it again with a right click > Actions > Launch Server Wizard on the server node. |
| When using Kerberos authentication, the user and password properties are not required, as the authentication is delegated to Kerberos. |
Once the connection properties are set, Kerberos optionally configured, you can click on connect and reverse your schemas and tables, as usual.
Simply follow the wizard as for any other traditional database:

JDBC URL syntax
Defining the correct JDBC URL and parameters might be delicate as it depends a lot on the Hive server and network configuration, if Kerberos is used, what Hadoop distribution is used, and more…
We’ll take a little time here to give advice and examples of URLs with explanations about its structure.
First, the Hive JDBC URL must follow the given syntax in Semarchy xDI:
<jdbc:semarchy:handler1>:<Hive JDBC Driver Class>:<JDBC URL>Example:
jdbc:semarchy:handler1:org.apache.hive.jdbc.HiveDriver:jdbc:hive2://quickstart.cloudera:10000/defaultPart |
Description |
Example |
jdbc:semarchy:handler1 |
The first part is present because we’re using a custom Semarchy xDI driver which helps us to handle the Kerberos security seamlessly. It is mandatory to use Kerberos. |
jdbc:semarchy:handler1 |
Hive JDBC Driver Class |
The Hive JDBC Driver Class Name. |
org.apache.hive.jdbc.HiveDriver |
JDBC URL |
Hive JDBC URL |
jdbc:hive2://quickstart.cloudera:10000/default |
JDBC URL examples
Example of URL to connect to Hive server
jdbc:semarchy:handler1:org.apache.hive.jdbc.HiveDriver:jdbc:hive2://quickstart.cloudera:10000/defaultExample of URL to connect to Hive server secured with Kerberos
jdbc:semarchy:handler1:org.apache.hive.jdbc.HiveDriver:jdbc:hive2://quickstart.cloudera:10000/default;principal=hive/quickstart.cloudera@CLOUDERABelow are some JDBC URL properties that are usually required when using Kerberos:
Property |
Description |
Example |
principal |
Kerberos principal to connect with. |
principal=hive/quickstart.cloudera@CLOUDERA |
HDFS temporary storage
Most of the Hive Templates are using HDFS operations to optimize the processes and use the native loaders.
The Hive Metadata therefore requires an HDFS connection to create temporary files while processing.
Follow these steps to configure the HDFS Temporary folder:
-
Create an HDFS Metadata or use an existing one
-
Define in this Metadata the temporary HDFS folder where these operations should be performed
-
Drag and drop the HDFS Folder Metadata in the Hive Metadata
-
Rename the Metadata Link to HDFS
| Hive must have the permission to access this folder. |

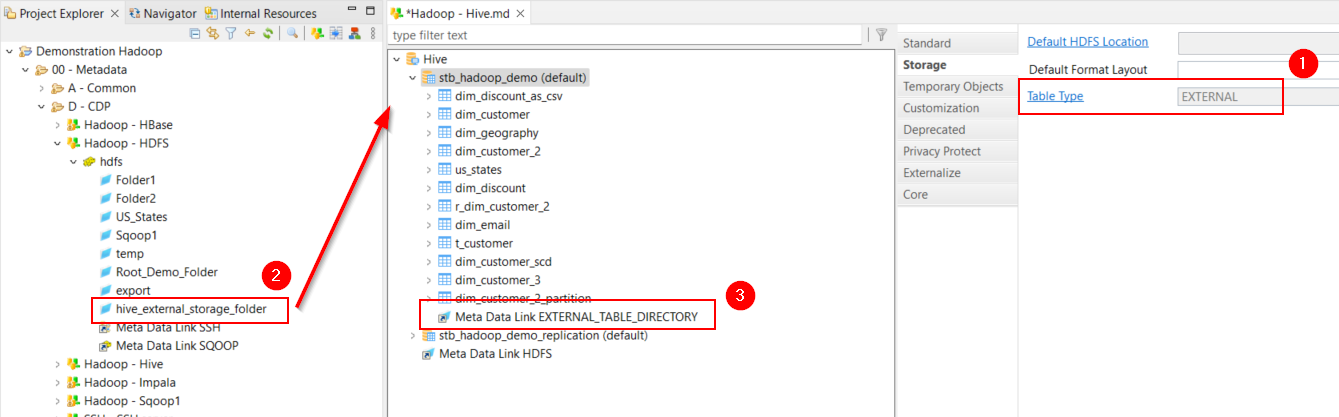
External and managed tables
There are two types of tables in Hive: * Managed Tables Data is stored and managed by Hive. * External Tables Data is stored in an external location defined by the user. ** In Semarchy xDI Designer, tables are configured by default as External Tables.
Managed tables
To define tables as Managed Tables:
-
Open Hive Metadata.
-
Click the desired schema.
-
Go to the Storage finger tab.
-
Change the Table Type to MANAGED.
All tables of the current schema are defined as managed.
External tables
To define tables as External Tables:
-
Open Hive Metadata.
-
Click the desired schema.
-
Go to the Storage finger tab.
-
Change the Table Type to EXTERNAL.
This is the default value. -
Drag and Drop the HDFS folder used to store tables' data onto the schema node.
-
Rename the created Metadata Link to EXTERNAL_TABLE_DIRECTORY
Create your first mappings
Your Metadata being ready and your tables reversed, you can now start creating your first Mappings.
You can use Hive technology in Semarchy xDI the same way as any other database.
Drag and drop your sources and targets, map the columns as usual, and configure the Templates accordingly to your requirements.
Example of Mapping loading data from HSQL into Hive:

Example of Mapping loading data from HSQL to Hive with rejects enabled:

Example of Mapping loading a delimited file into Hive:

Example of Mapping loading data from Hive to HSQL, using a filter and performing joins:

| For further information, consult the Template’s and parameters description. |
Sample project
The Hadoop component is distributed with sample projects that contain various examples and files. Use these projects to better understand how the component works, and to get a head start on implementing it in your projects.
Refer to Install components in Semarchy xDI Designer to learn about importing sample projects.