| This is documentation for Semarchy xDI 5.3 or earlier, which is no longer supported. For more information, see our Global Support and Maintenance Policy. |
Getting Started with HBase
Connect to your Data
The first step, when you want to work with HBase in Semarchy xDI, consists of creating and configuring the HBase Metadata.
Here is a summary of the main steps to follow:
-
Create the HBase Metadata
-
Configure the Metadata
-
Configure Kerberos security (optional)
-
Reverse the namespaces and tables
Below, a quick overview of those steps:
Create the Metadata
Create first the HBase Metadata, as usual, by selecting the HBase technology in the Metadata Creation Wizard.
Choose a name for this Metadata and go to next step.
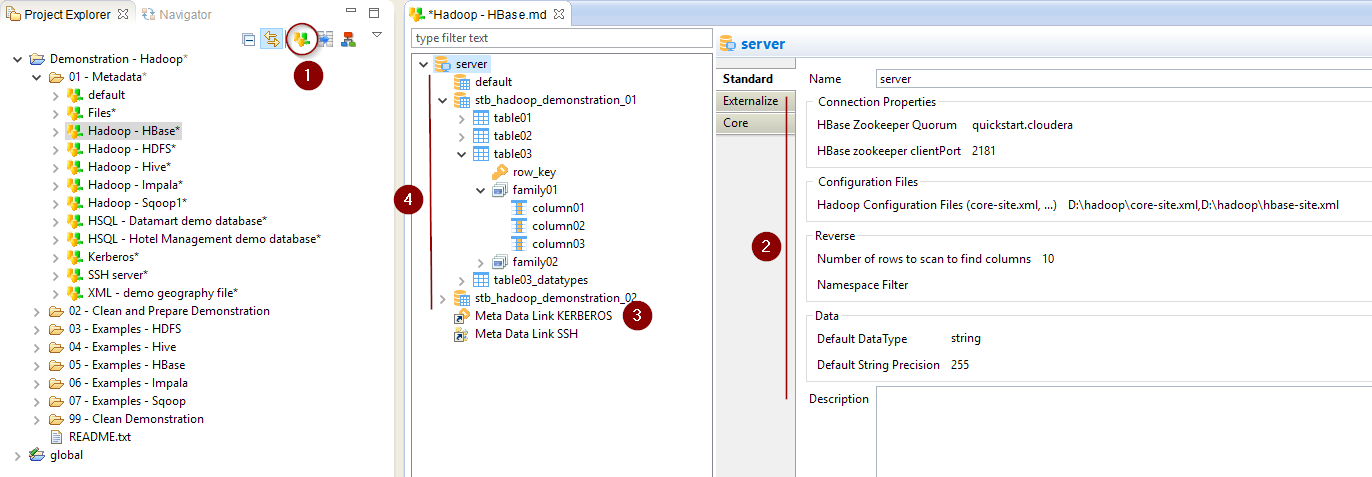
Configure the Metadata
Your freshly created HBase Metadata being ready, you can now start configuring the server properties, which will define how to connect to HBase.
The following properties are available:
Property |
Mandatory |
Description |
Example |
HBase Zookeeper Quorum |
Yes |
Comma separated list of HBase servers in the Zookeeper Quorum |
quickstart.cloudera |
HBase Zookeeper Client Port |
Yes |
Network port on which the client will connect |
2181 |
Hadoop Configuration Files |
Recommended |
Hadoop stores information about the services properties in configurations file such as core-site.xml and hbase-site.xml. |
D:\hadoop\core-site.xml,D:\hadoop\hbase-site.xml |
Number of rows to scan to find columns |
No |
HBase doesn’t store Metadata about the columns that exist in a table. |
100 (default value if not set) |
Namespace Filter |
No |
Optional regular expression used to filter the namespaces to reverse. |
*
stb_hadoop_% |
Default DataType |
No |
This property offers the possibility to define the default type to use, when the type is not defined on a column in the Metadata. See Datatypes Management for more information. |
string |
Default String Precision |
No |
Default precision (size) to be used for string columns. As for the Datatypes, this is used to help Semarchy xDI manipulating data when reading from HBase. |
255 |
Configure the Kerberos Security (optional)
When working with Kerberos secured Hadoop clusters, connections will be protected, and you’ll therefore need to specify in Semarchy xDI the credentials and necessary information to perform the Kerberos connection.
A Kerberos Metadata is available to specify everything required.
-
Create a new Kerberos Metadata (or use an existing one)
-
Define inside the Kerberos Principal to use for HBase
-
Drag and drop it in the HBase Metadata
-
Rename the Metadata Link to 'KERBEROS'
Below, an example of those steps:
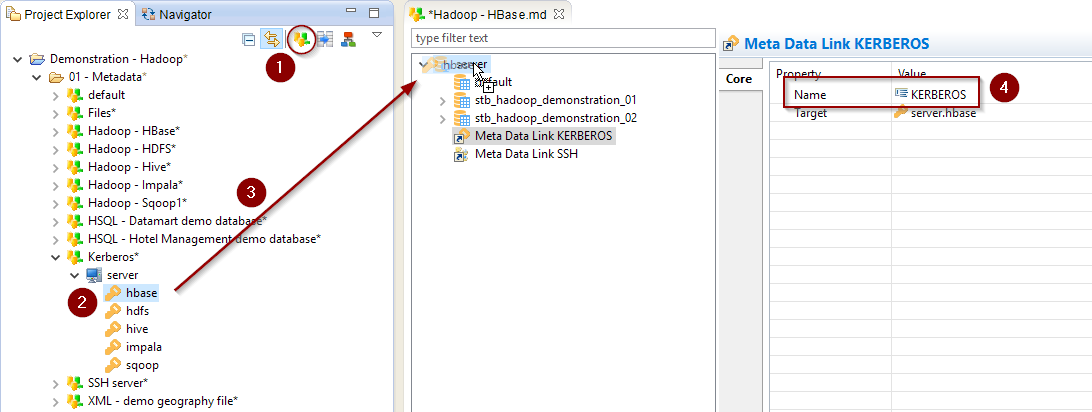
| Refer to Getting Started With Kerberos for more information. |
Reverse of the namespaces and tables
Your Metadata is now ready to begin reversing the existing namespaces and tables.
When performing the reverse, Semarchy xDI connects to HBase, retrieves the namespaces and tables, with their structures, and creates the associated Metadata structure.
To reverse your items simply right click on the desired node and choose Actions > Reverse [All]
-
On the server node: all the namespaces and corresponding tables will be reversed
-
On a namespace node: all the tables of the namespace will be reversed
-
On a table node: only the structure of the selected table is reversed
Below an axample on the server, to reverse everything:
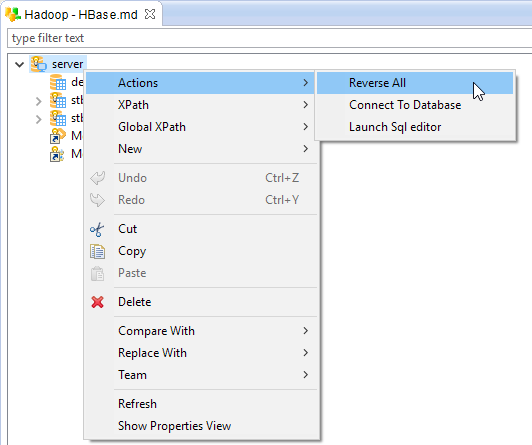
| You can use the "Namespace Filter" property of the server node if you want to filter the namespaces to reverse |
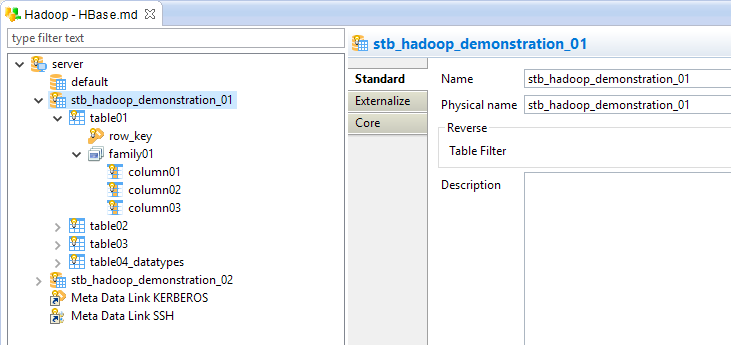
Metadata Additional Details
Namespace node
The namespace node is the container for tables, and physically exists on the HBase server.
| You can use the right click > Actions > Reverse menu to reverse the tables of the selected namespace |
The following properties are available:
Property |
Description |
Example |
Name |
Logical label used in Semarchy xDI to identify the namespace node |
namespace01 |
Physical name |
Real name on the HBase server |
namespace01 |
Table Filter |
Optional regular expression used to filter the tables to reverse when performing a reverse on this namespace. |
*
table% myTable_% |
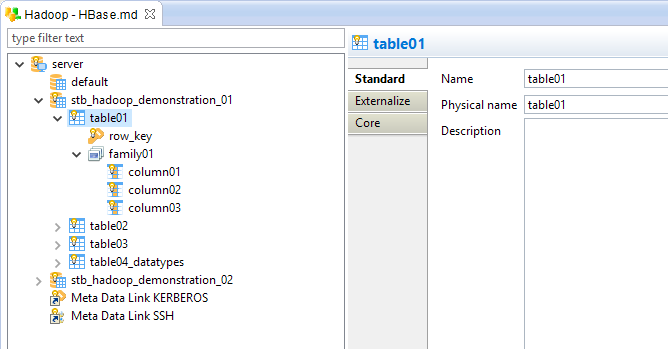
Table node
The table node represents an HBase table, which contains families, containing themselves columns.
| You can use the right click > Actions > Reverse menu to reverse automatically the structure of the selected table |
The following properties are available on table node:
Property |
Description |
Example |
Name |
Logical label used in Semarchy xDI to identify the table node |
table01 |
Physical name |
Real name on the HBase server |
table01 |
Family Node
The following properties are available on a family:
Property |
Description |
Example |
Name |
Logical label used in Semarchy xDI to identify the family node |
family01 |
Physical name |
Real name on the HBase server |
family01 |
Column node
Row Key
In HBase, every row is uniquely identified by a 'Row Key', which is a special field associated to each row inserted.
We decided in Semarchy xDI to represent it as a specific column, to offer the possibility to fill its value at write and read.
This special column is created automatically at reverse by Semarchy xDI, and is represented with a little key icon
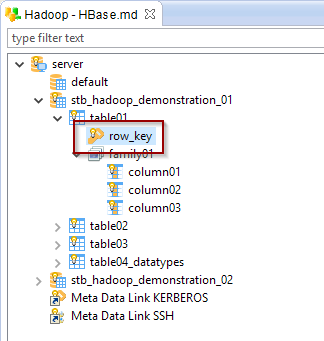
If needed, you can also create it manually, this is simply a column which must be named 'row_key', and in which the Advanced/Is Row Key property is checked.
Note that only one column should be set as Row Key, and we advise to let Semarchy xDI create it automatically at reverse to avoid any issue.
Column
In HBase the columns contained in a row are not pre-defined.
Meaning that there can be different number of columns from row to row, which can be completely different.
When reversing the columns, StamSemarchy xDIbia scans the number of rows specified on the server node to find all the columns available in these.
As a consequence, the reversed Metadata might not contain all the existing columns, depending if they were present in the scanned rows or not.
If needed, you can easily add new columns manually in the Metadata with a right click > New Column menu on a family.
The columns are dynamically managed by HBase when inserting data.
Property |
Description |
Example |
Name |
Logical label used in Semarchy xDI to identify the column node |
column01 |
Physical name |
Real name on the HBase server |
column01 |
Type |
Datatype representing the data contained in this column. |
string |
Precision |
Precision (size) of the data contained in this column for the specified type. |
255 |
Scale |
Scale to use for the specified datatype. |
10 |
Datatypes Management
HBase stores everything as bytes in its storage system and it doesn’t have a notion of datatypes for the columns.
We decided in Semarchy xDI to offer the possibility to specify datatypes on the columns to ease data manipulation between different technologies.
This helps Semarchy xDI to have an idea of what is contained in a column, to treat it correctly when reading data from HBase.
This helps also to define the correct SQL types and size in the temporary objects created and manipulated when loading data from HBase into other database systems such as Teradata, Oracle, Microsoft SQL Server…
HBase importtsv tool
HBase is usually shipped with a native command line tool called 'importtsv'.
This tool is used to load data from HDFS into HBase and is optimized for having good performances.
The Semarchy xDI Templates offer the possibility to use this method to load data into HBase.
For more information, please refer to HBase importtsv Tool page which explains how to configure the Metadata and Mappings to use it.
Create your first Mappings
Your Metadata being ready and your tables reversed, you can now start creating your first Mappings.
For the basics HBase is not different than any other database you could usually use in Semarchy xDI.
Drag and drop your source and target and map the columns as usual.
Example of Mapping loading data from HSQL to HBase:
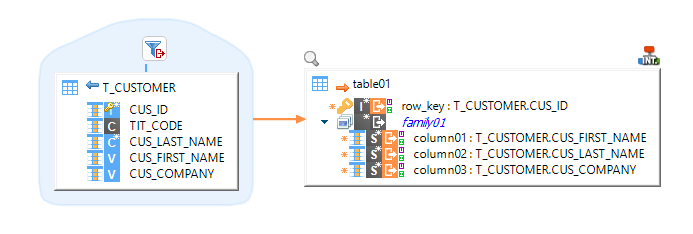
Example of Mapping loading data from HBase to HSQL, with a filter on HBase:
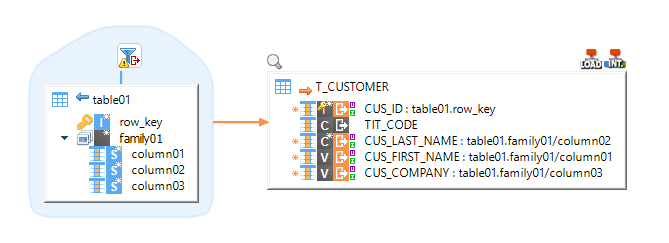
| Filters must use the HBase filter syntax, such as SingleColumnValueFilter ('family01', 'column02', = , 'binary:gibbs'). Refer to the HBase documentation and examples in the Demonstration Project for further information. |
Example of a join between two HBase tables to load a target HSQL table:
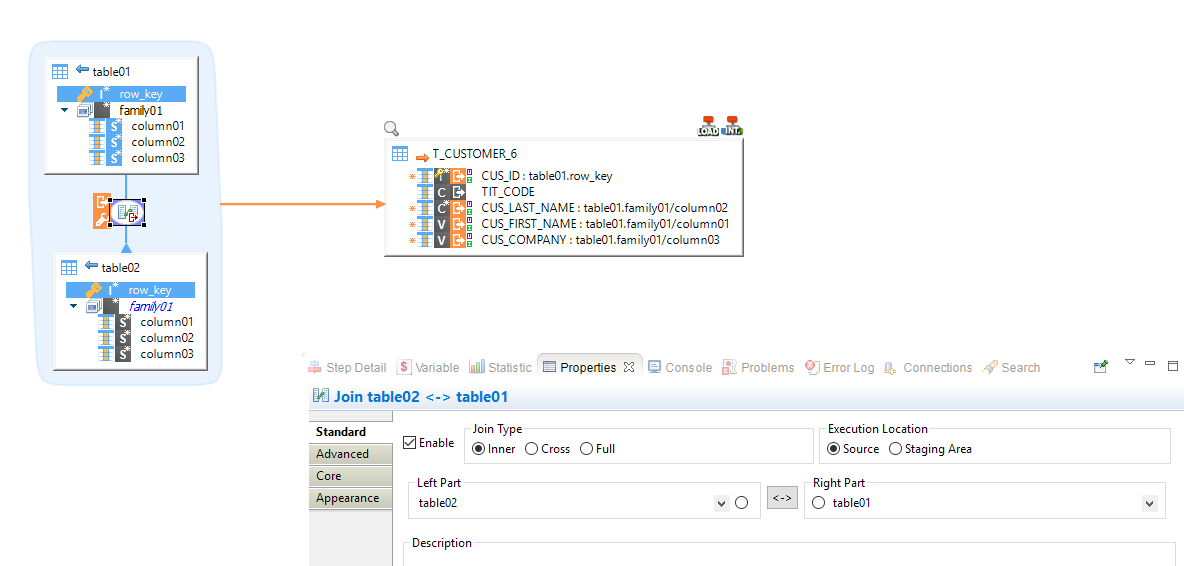
The join order defined with the Left Part / Right Part of the properties is important.
Notice the little triangle on the joined table link (table02) in the Mapping.
In this example we are retrieving all the table01 rows from which the Row Key exists in the table02.
| You cannot use the columns of the joined table (table02) in the target table, the joined table is only used as a 'lookup' table. |
Sample Project
The Hadoop Component ships sample project(s) that contain various examples and use cases.
You can have a look at these projects to find samples and examples describing how to use it.
Refer to Install Components to learn how to import sample projects.