















































Semarchy 2024.3 en bref
Semarchy 2024.3 est une version courante (MS, pour Mainstream Support) qui apporte de nouvelles fonctionnalités puissantes à nos modules Data Intelligence, Data Integration et Data Management. Voici un aperçu de ce que vous y trouverez :
Fonctionnalités principales de Data Integration (xDI) 2024.3
API de gestion de fichiers delivery
Connecteur SAP S/4HANA
Mise à jour de connecteurs
Sérialiseurs et désérialiseurs
Fonctionnalités principales de Data Management (xDM) 2024.3
Ajout d’enrichisseurs de données par IA générative
Enrichisseurs intelligents de classification de données
Mise à jour du connecteur Purview
Étape automatique de modification des métadonnées de workflow
Démarrage de workflows à partir d’un enregistrement parent sélectionné
Fonctionnalités principales de Data Intelligence (xDM) 2024.3
Améliorations des initiatives en matière de données
Amélioration des métriques
Enrichisseurs d’actifs de données
Gestion de nœuds frères (siblings)
Ajout et amélioration de collecteurs de données (harvesters)
Amélioration de l’authentification SSO et de la synchronisation de groupes
Des détails sur ces fonctionnalités sont disponibles dans la documentation.
Semarchy 2024.3 en détail
Semarchy Data Integration (xDI)
API de gestion de fichiers delivery
xDI Runtime dispose d’une nouvelle API REST pour gérer les fichiers delivery, permettant par exemple de répertorier les référentiels configurés et d’y ajouter ou d’en supprimer des fichiers delivery. Jusqu’à présent, ces opérations n’étaient disponibles que via la ligne de commande. Les points de terminaison de cette API REST offrent aux utilisateurs une plus grande marge de manœuvre et améliorent considérablement la gestion automatisée de ces fichiers.
Connecteur SAP S/4HANA
xDI 2024.3 intègre un nouveau connecteur dédié à SAP S/4HANA, la solution ERP leader auprès de la plupart des entreprises. Bien que cette application héberge des données parmi les plus critiques, il est souvent difficile de les exploiter ailleurs.
Ce connecteur permet aux utilisateurs d’intégrer de manière transparente les sources SAP S/4HANA via des interfaces BAPI et des DataSources au sein de votre écosystème.
Mise à jour de connecteurs
Le connecteur Azure Service Bus a été lancé plus tôt cette année dans notre cycle de publication. Cette nouvelle version donne à présent la possibilité de souscrire à des rubriques et abonnements, ainsi que de planifier l’envoi de messages. Le connecteur Azure Blob Storage prend également en charge l’authentification par clé d’accès au compte de stockage Azure. Ces fonctionnalités améliorent les interactions avec Azure Service Bus et élargissent le choix de moyens d’authentification sur Azure Blob Storage.
Sérialiseurs et désérialiseurs
Dans cette version, nous poursuivons nos efforts pour fournir de nouveaux modèles de procédure de (dé)sérialisation de données. Cette version présente un nouveau modèle pour désérialiser les données Oracle de type « chaîne de caractères » en JSON, ainsi qu’un nouveau modèle de sérialiseur JSON optimisé pour l’intégration de Snowflake. Pour rappel, les (dé)sérialiseurs constituent un moyen simple et normalisé de transformer et de déplacer des données dans différents formats.
Semarchy Data Management (xDM)
Ajout d’enrichisseurs de données par IA générative
Depuis le lancement en version 2024.2 des premiers enrichisseurs par IA générative (GenAI), nous avons poursuivi le développement de nouveaux plugins GenAI intégrés à l’intention des concepteurs d’applications xDM. Ces derniers peuvent désormais exploiter pleinement les modèles d’IA les plus avancés tels que GPT-4, Google Gemini et Amazon Titan, lesquels sont disponibles auprès de fournisseurs de premier plan tels que Microsoft Azure AI, Google Vertex AI et Amazon Bedrock.
Enrichisseurs intelligents de classification de données
Des enrichisseurs intelligents de classification sont désormais disponibles pour automatiser la catégorisation des données avec peu (« classification few shot »), voire pas (« classification zero shot ») d’entraînement préalable sur des jeux de données étiquetées. Ces derniers permettent de gagner du temps et d’améliorer la précision du classement d’enregistrements de données, moyennant un minimum d’entraînement de modèles.
Ces nouveaux plugins analysent du texte et sont en mesure d’attribuer des enregistrements de données à des catégories prédéfinies, allégeant ainsi les tâches laborieuses de classement manuel. Les concepteurs pourront comme d’habitude configurer en toute simplicité les paramètres nécessaires à l’exécution de ces enrichisseurs, tandis que les utilisateurs finaux tireront parti de l’intégration transparente des capacités automatisées et intelligentes de classification de leurs enregistrements de données, directement dans leurs applications Semarchy. Ces deux enrichisseurs s’appuient sur des modèles accessibles via l’API Hugging Face, et permettent de choisir les modèles les plus pertinents selon la nature des données à classer.
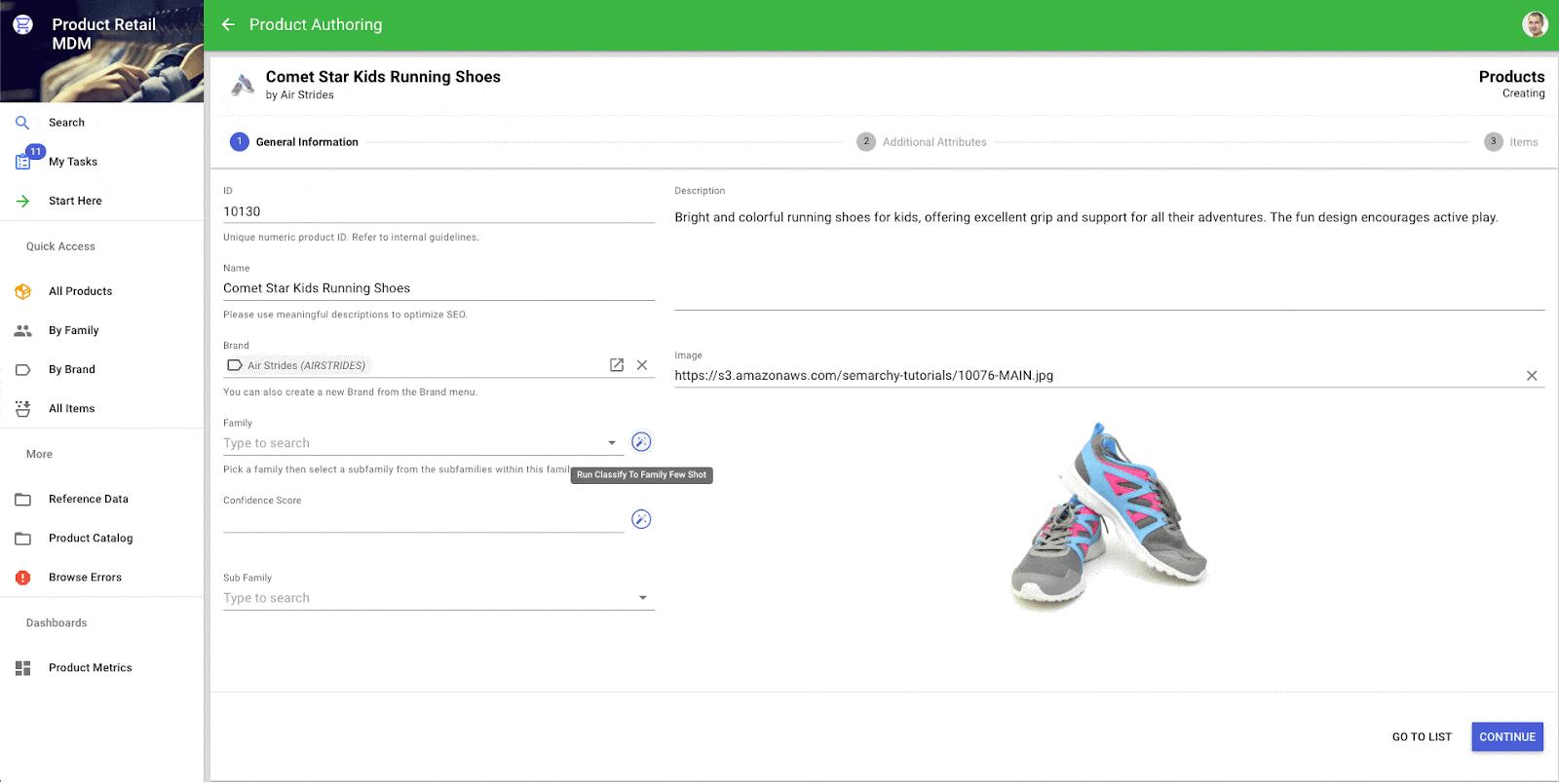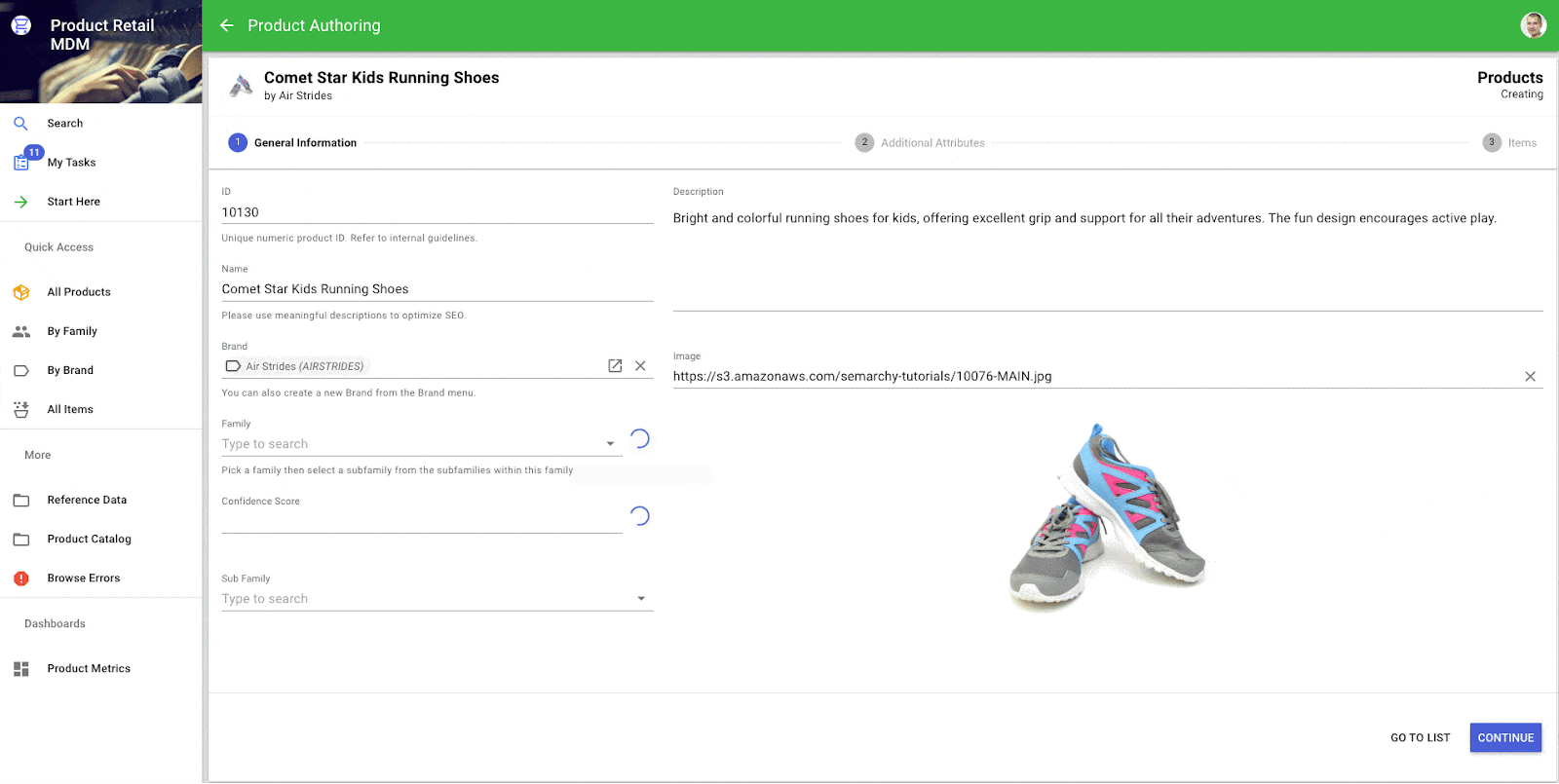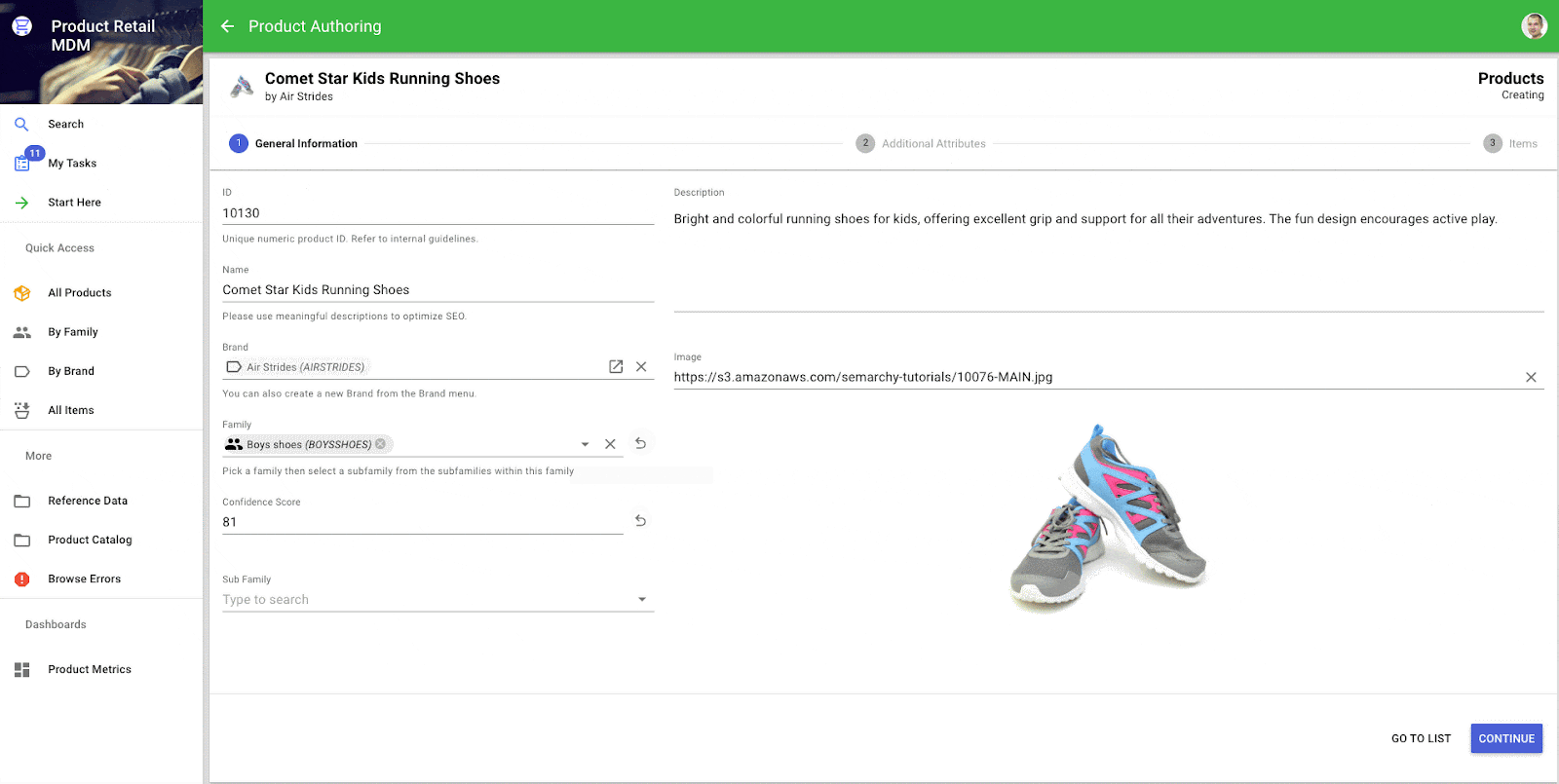
Classification automatisée d’un produit à l’aide d’un enrichisseur intelligent.
Mise à jour du connecteur Purview
La dernière mise à jour du connecteur Purview introduit la capacité de publier des entités xDM dans un produit de données (data product) Microsoft Purview. Ces actifs, présentés comme des données d’enregistrement golden, sont désormais affichés aux côtés du logo Semarchy xDM, de sorte que les utilisateurs puissent les distinguer aisément parmi d’autres data products.
Étape automatique de modification des métadonnées de workflow
Dans le module Workflow Builder, une nouvelle étape automatisée appelée « Modifier Métadonnées Workflow » permet de définir la valeur de certaines propriétés de workflows, telles que leur description, leur commentaire initial, leur degré de priorité, leur date d’échéance et les métadonnées du responsable de la tâche suivante, au moyen d’expressions SemQL et de valeurs littérales. Parmi ses applications potentielles, cette nouvelle fonctionnalité permet de planifier efficacement des tâches en permettant aux concepteurs de définir dynamiquement leurs dates d’échéance en fonction de la date actuelle ou du contenu des enregistrements de données traités.
Les commentaires ou les descriptions fournissent par ailleurs un contexte aux instances de workflow démarrées automatiquement.
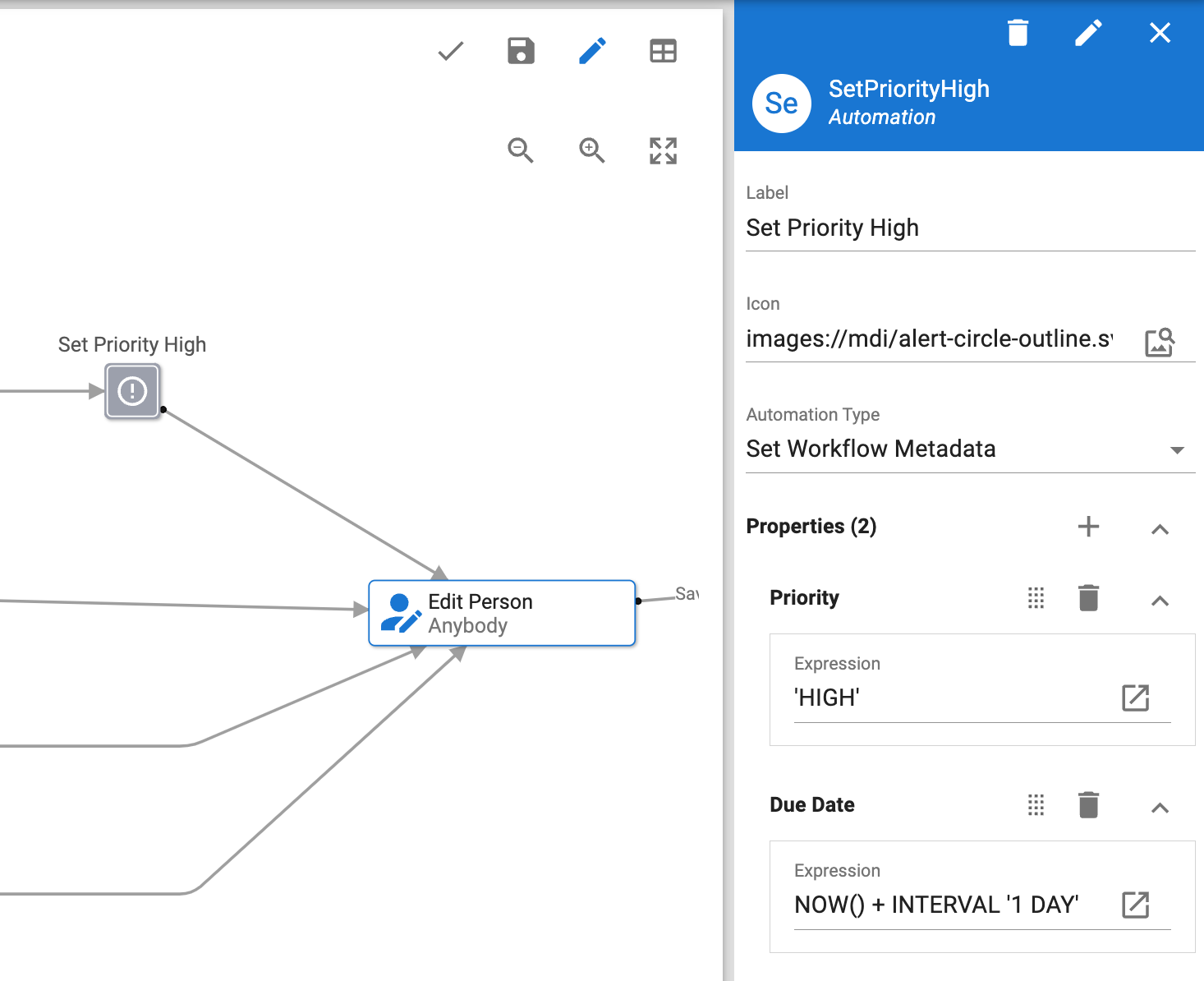
Configuration automatique du degré de priorité et de la date d’échéance d’un workflow.
Démarrage de workflows à partir d’un enregistrement parent sélectionné
Simplifiez les relations complexes entre données en déclenchant des workflows à partir d’un enregistrement parent, pour améliorer l’intégrité des données et faciliter votre expérience de travail avec des données hiérarchisées.
Dans le module Workflow Builder, les concepteurs peuvent désormais configurer des workflows de sorte qu’ils démarrent à partir d’un enregistrement parent donné, en sélectionnant le contexte de démarrage « Démarrer depuis le Parent Sélectionné ». Cette nouvelle fonctionnalité permet aux utilisateurs de lancer des workflows sur les entités filles et facilite la création d’enregistrements en les liant automatiquement à leur enregistrement parent. De plus, ce nouveau contexte de démarrage peut être utilisé via l’API REST d’administration de workflow à l’aide du paramètre de démarrage « parentRecordSelectionFilter ».
Semarchy Data Intelligence
Améliorations des initiatives en matière de données
Les actions menées par les parties prenantes aux initiatives en matière de données sont désormais visibles dans une interface améliorée et plus intuitive. Celle-ci apporte une meilleure visibilité à leurs contributions, et permet d’en garantir la traçabilité. Cela devrait renforcer la collaboration et faciliter le suivi de l’avancement des initiatives.
Amélioration des métriques
Les métriques et les badges jouent un rôle clé dans la gouvernance de données. Cette nouvelle version apporte des améliorations supplémentaires au langage d’expression utilisé pour définir des règles pouvant servir à créer ou modifier des badges ou à calculer des métriques. Les utilisateurs disposent à présent de moyens à la fois plus puissants et plus souples pour améliorer leurs politiques de gouvernance à l’aide de métriques et de badges.
Enrichisseurs d’actifs de données
Semarchy définit l’enrichissement de données comme étant le processus de modification, de transformation ou d’amélioration d’éléments par un mécanisme automatique ou semi-automatique. Dans Data Intelligence, la détection d’actifs est à présent automatisée au moyen d’un enrichisseur qui vise à unifier les flux et à détecter des groupes de nœuds frères (siblings) pouvant provenir d’une même source. La détection et la gestion des fratries de nœuds sont cruciales pour préserver la qualité des données, notamment dans une optique de conformité avec les politiques de gouvernance.
Les enrichisseurs d’actifs détectent des jeux de données frères (siblings) dans le cadre d’une initiative.
Gestion de nœuds frères (siblings)
La création de lignées d’actifs permet également de détecter manuellement des nœuds frères, ou siblings. Cette fonction s’intègre harmonieusement avec les enrichisseurs d’actifs automatisés, en suivant l’ensemble des améliorations apportées aux siblings, tout en conservant le résultat des détections manuelles précédentes. La coordination de la détection automatisée et manuelle de siblings permet de gérer ces actifs de manière souple et performante.
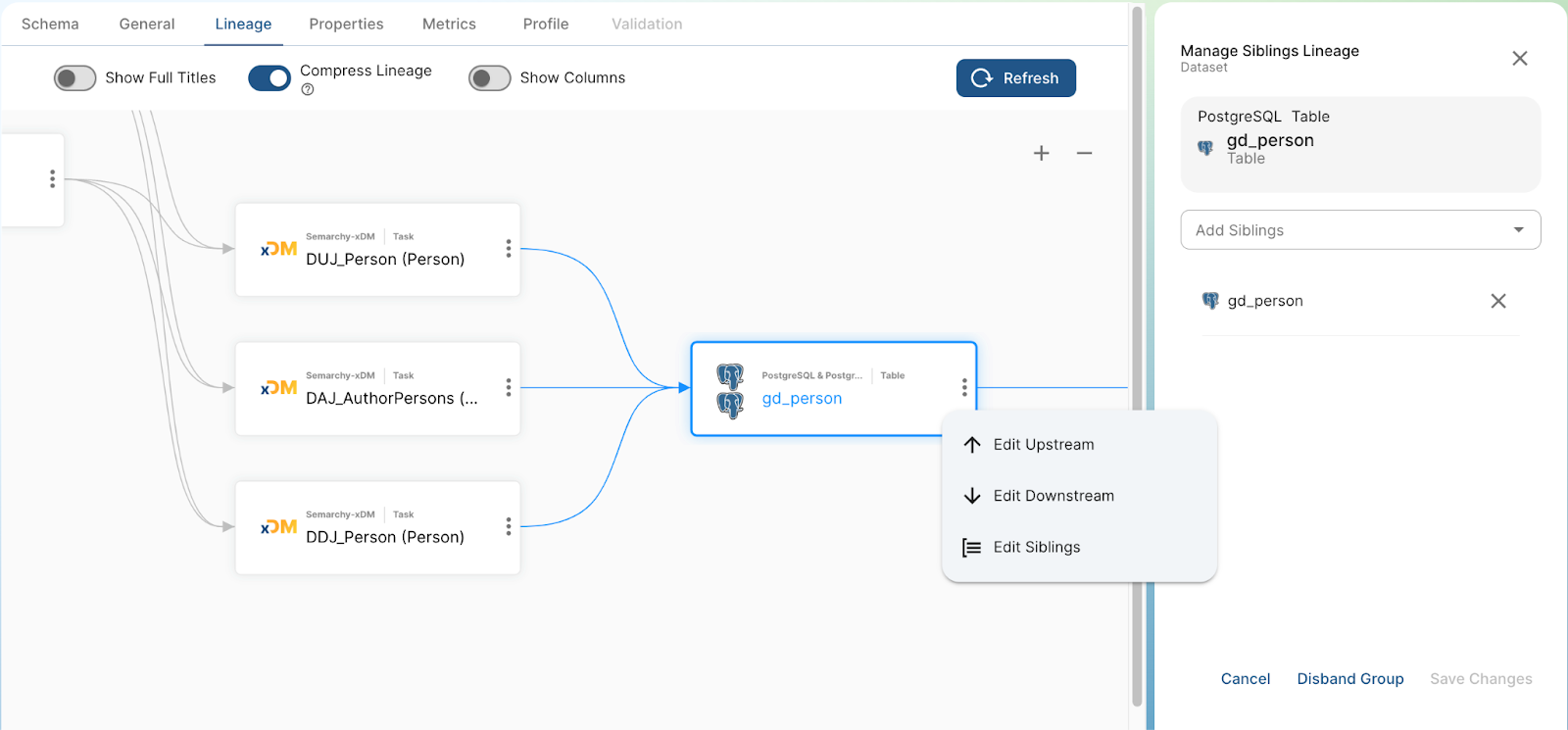
Manage siblings in the asset lineage
Ajout et amélioration de collecteurs de données (harvesters)
Nous cherchons constamment à élargir la gamme de technologies prises en charge par Data Intelligence. Dans cette nouvelle version, nous avons concentré nos efforts sur l’amélioration des capacités de capture de lignages à partir de technologies de bases de données et sur le renforcement des couches de sécurité. Cette approche nous permet de fournir des harvesters agiles et personnalisés répondant aux besoins opérationnels de nos clients.
Amélioration de l’authentification unique et de la synchronisation de groupes
Bénéficiez d’une expérience utilisateur plus fluide grâce à une synchronisation optimisée du système d’authentification. La capture d’informations sur la structure des groupes d’utilisateurs a été améliorée et l’authentification unique (SSO) a été simplifiée pour faciliter les interactions des utilisateurs avec Data Intelligence.
À propos de la Unified Data Platform de Semarchy
Semarchy, leader sur le marché de la gestion des données de référence ( master data management ) et de l’intégration des données, permet aux organisations de générer rapidement de la valeur métier à partir de leurs données en 12 semaines. Sa data plateforme (xDM + xDI) permet aux organisations de toute taille de découvrir, d’intégrer, d’enrichir, de gérer, de gouverner et de rapporter des informations essentielles dispersées dans des systèmes cloisonnés.
Semarchy est disponible en version on-premise et peut être déployé nativement sur les market places cloud les plus populaires telles que Microsoft Azure, Amazon Web Services (AWS) et Google Cloud Platform (GCP), ou géré en tant que service, avec le soutien d’un riche écosystème de partenaires de logiciels en tant que service (SaaS) et de services professionnels.
Nous faisons évoluer notre approche de l’innovation
Notre obsession ? la satisfaction des clients. Pour cela nous déployons des mises à jour régulières et trimestrielles de la data plateforme pour les solutions de Data Management xDM, Data integration xDI et Data Intelligence xDG. Nos clients, qui font figure de pionniers dans le domaine de la Data, bénéficieront d’un soutien continu de notre part pour renforcer leur stratégie.
En savoir plus sur nos mises à jour de la plate-forme et notre cadence de maintenance.
Explorez Semarchy 2024.3
Partagez cette publication




Featured Resources

L’état du Data Management en 2026
